Chapter 5 Modelling User Profiles
The whole thing starts with massive, passive data collection. No matter which website we visit or which app we use: We leave a digital footprint. These footprints are compiled for individual users and form so-called user profiles. A set of similar profiles is then aggregated to user segments, which aim at describing a homogeneous set of users with similar preferences and interests.
5.1 What is look-a-like modelling?
Lookalike modelling is “finding new people who behave like current customers – or like a defined segment. The topic is hot, but there’s deliberate mystery about the method and its accuracy” 2 The following section, will demystify the method and bring some science to it.
The basic idea is to find users who belong to a defined audience. Starting from a seed audience such as users who already converted or users that have state to belong to an audience through an survey, the idea is to train a statistical model to identify which user actions separate that user cluster from other users. Let’s have a look at a simple example to predict a user’s gender. The data usually used to create the lookalike models consists of the websites a user has visited in the past and one outcome variable. In this example that outcome variable is the user’s gender.
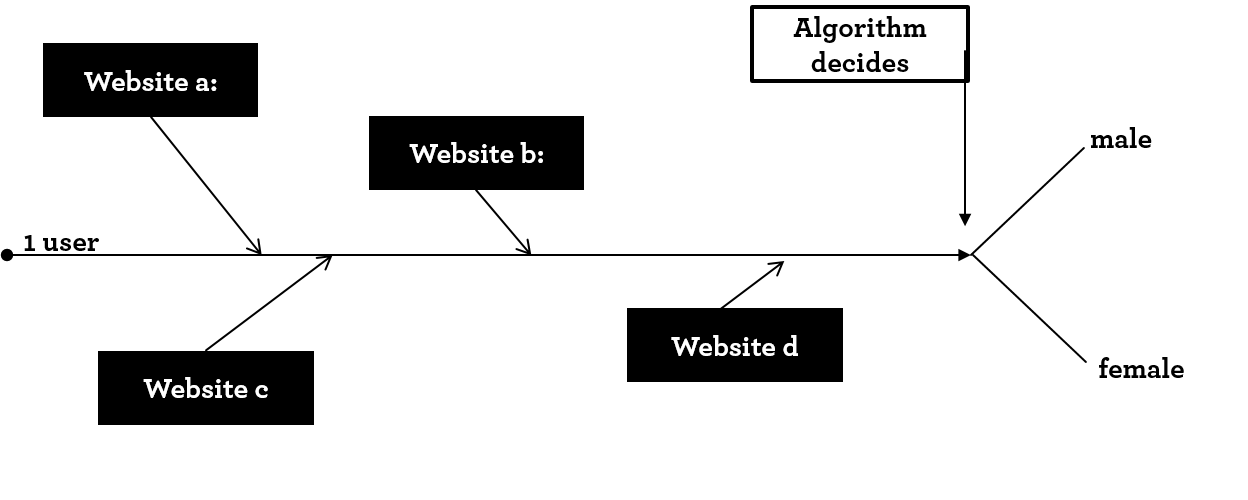
Schematic view of the look-a-like prediction process
That information is fed into various algorithms to train models on the data. One such model can be a tree-based model. The following chart exemplifies such a “Tree” model. As basis we used 20000 users and just 4 websites to classify users depending on their gender. The websites are illustrated as boxes in the middle. In the first step the model tells us that if a user visited chip.de (N>=1) he is with a probability of 65% male. As a more complex example down the tree is if a user did not visit chip.de but gesuende.de she is with 73% female. That tree gets more complex if users can be segmented using more websites.
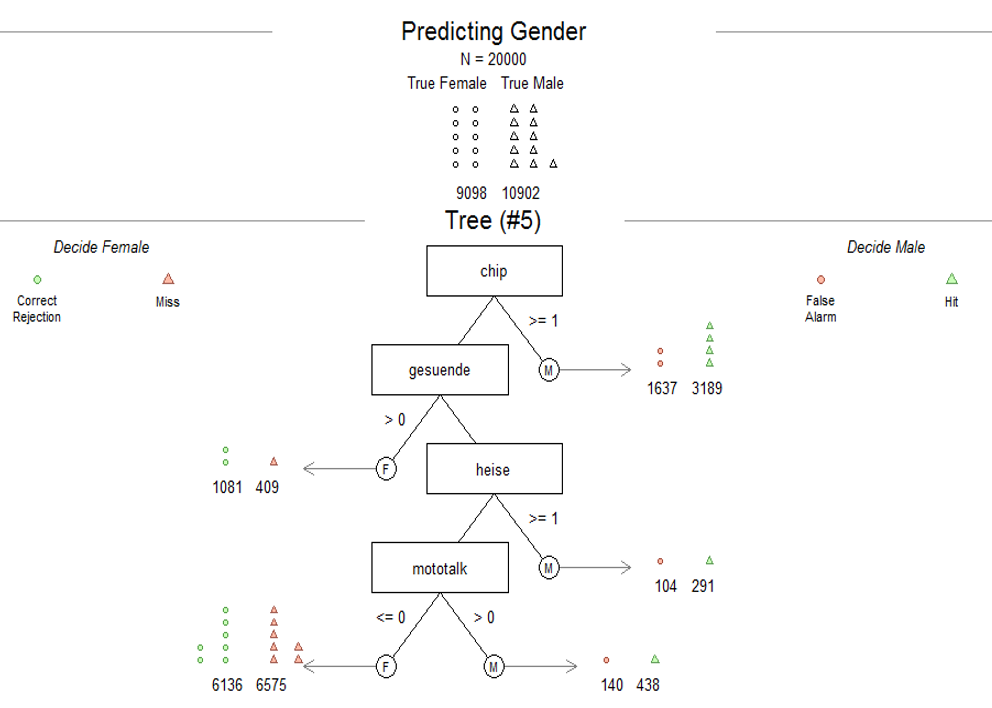
Example tree-algorithm to decide on user attribute
Next, we discuss several factors that influence how well lookalike modelling approaches work.
5.2 Factors influencing modelling accuracy
Model accuracy describes how well the model classifies users. As a simple measure, we take the prediction accuracy defined as the number of correctly classified users as a percentage of all classified users. For the previous example of predicting a user’s gender we see that the accuracy is a function of how many websites are used. In the example chart 62% of all users are correctly classified by just using 20 randomly selected websites as data source. That number increases to roughly 73% when the model has access to 500+ websites. After that, additional websites do not add predictive value.
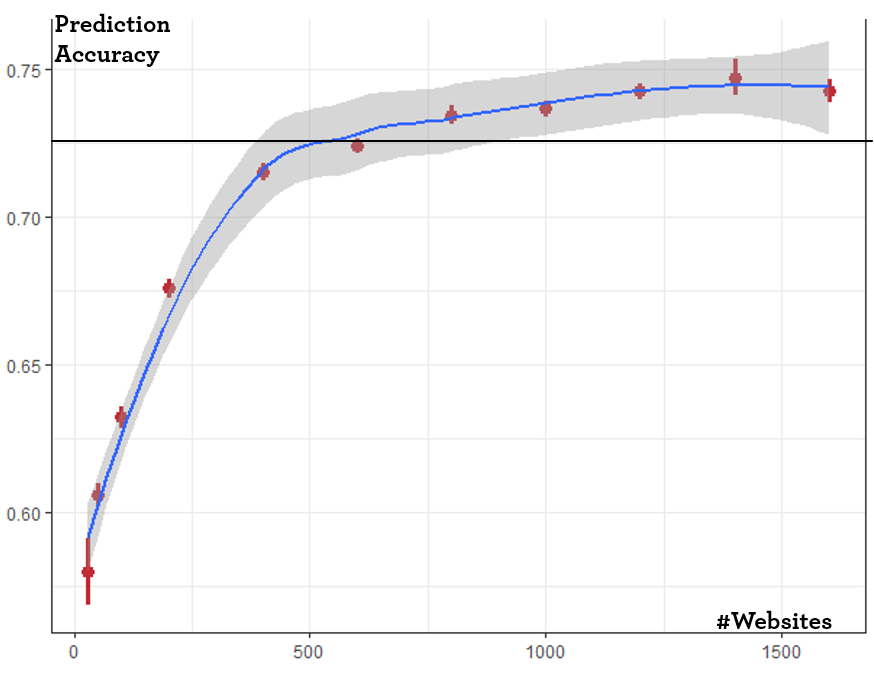
Prediction accuracy is dependent on website universe
This means that data providers theoretical prediction quality depends on number of websites their tracking code is implemented on. Small scale data providers with a small “tracking universe” will very likely have a hard time to use lookalike modelling approaches or conversely their prediction accuracy will be subpar.
Another important aspect is the so-call prediction threshold. Machine learning algorithms usually output a probability that a user for each user classification. For example, the predicting a user’s gender might result in a prediction 80% male, 20% female. In a second step, the system applies a threshold to label the user. For users where the output is uncertain e.g. 50% male/female it depends on the system setting if this user’s gender is labeled “unknown”. The threshold setting introduces a moral challenge for the data provider. Increasing the threshold increases the prediction accuracy. Only users are classified for which the algorithm is certain that the prediction is correct. However, setting the threshold higher, reduces the number of users classified. Hence, the scale which the data provider aims to sell.
The following chart exemplifies the relationship.
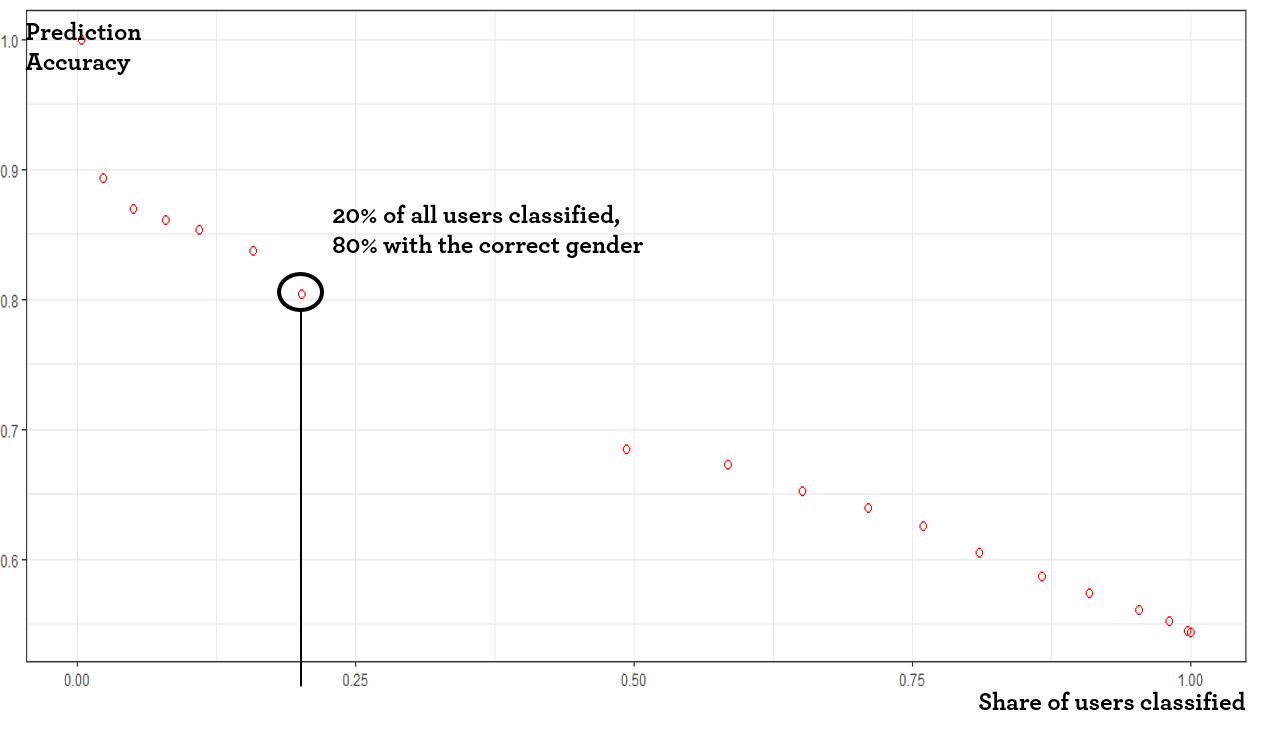
Prediction accuracy is dependent on the share of users classified
In the dataset studied, we see that if we aim for a prediction accuracy of 80% for gender, we can only classify 20% of all users. This relationship depends on the data provider’s scale (see previous point) as well as the classification (gender is different than age brackets).
In general, a models prediction accuracy depends on the classification type. There are two simple reasons for that; a) an algorithmic and b) an informational reason. For the algorithmic reason, some classification types are harder than others. The gender classification is binary (e.g. coin flip). Hence the base rate is 50%. If the algorithm should predict age brackets there are multiple options to pick (20-30 vs 30-40 vs 40-50, …). The base-rate is consequential lower which means that an algorithm predicting at random will have a worse prediction accuracy in the case of the age prediction. The informational aspect touches the fundamentals of lookalike modelling; there needs to be information in the features used. Users which belong to different classes need to have distinctively different website usage. If users belong to different classes but have the same behavior the model cannot successfully differentiate between them. The prediction accuracy will suffer. To stick with the age bracket example; users age 39 have a very similar website usage behavior compared to users age 41.
One point that is often mentioned by data providers is their superior machine learning / artificial intelligence / deep learning algorithm. While there might be cases (natural language processing or computer vision) where advanced AI have an edge, in most lookalike scenarios this is not the case. The data described in the last paragraphs is pretty clean and can be easily handled by off the shelf algorithms (e.g. XGBoost, random forest).
The AI label is often used in “sales” pitches to deflect from the really important questions; scale of tracking, threshold to predict and accuracy of different classification types.
Questions that advertisers should ask providers of lookalike models:
- How accurate are Lookalike models? What are the key factors?
- What is the effect of the number of websites used to measure user behavior?
- What is the effect of different Machine Learning algorithms?
- What is the effect the selection of websites used to measure user behavior?
- What is the minimum number of users needed to create models?
- Which attributes can reliably been used to create models?